Introduction
The release of DeepSeek-V4 is not just a technical iteration but a pivotal moment for China’s AI industry. From Huawei’s native adaptation to the capital competition among Tencent and Alibaba, this trillion-parameter model is reshaping the competitive landscape of domestic computing power. This article will delve into the industrial logic behind its technological breakthroughs, revealing the commercialization dilemmas and strategic choices faced by open-source model companies.

On April 24, 2026, the first indication that DeepSeek-V4 was more than just a model update did not come from Hugging Face or DeepSeek’s official announcement but from a live stream on Bilibili.
Huawei’s Ascend CANN official account hosted a live event titled “DeepSeek V4 Ascend Premiere.” The very act of a large model company launching a new model through a chip ecosystem’s official account was unusual.
If this were merely a routine upgrade with larger parameters, longer context, and better benchmark scores, it would belong to the daily arms race of the AI circle, at most leading developers to bookmark it on Hugging Face or product managers to share benchmark screenshots in their circles. However, this time, the V4-Pro’s 16 trillion total parameters, 49 billion active parameters, million-token context, MIT License open-source, and its connection to Huawei’s Ascend 950PR native adaptation turned the event into an “industrial signal.”
On the same day, Reuters reported that Tencent and Alibaba were involved in financing negotiations with DeepSeek. Just days earlier, the market had valued DeepSeek at around $10 billion, but this figure quickly rose to over $20 billion.
Chinese venture capital media were even more aggressive, reporting a pre-investment valuation of 300 billion RMB, a 50 billion RMB capital increase, and a 5 billion RMB minimum investment threshold. Domestic GPU concept stocks responded accordingly; as soon as DeepSeek-V4 launched, related ETFs and chip stocks surged. The capital market may not understand abbreviations like mHC, CSA, HCA, or DSA, but it comprehends a more straightforward narrative: DeepSeek is becoming the “nucleus” of the entire Chinese computing power industry chain, connecting all clues.
The Journey to DeepSeek-V4
Rewind 484 days.
On December 26, 2024, DeepSeek-V3 was released with 671 billion parameters, 37 billion active parameters, MoE architecture, and MLA attention mechanism. The official technical report cited a figure later quoted by global media: the complete training took approximately 2.788 million H800 GPU hours, translating to a training cost of about $5.57 million. A month later, DeepSeek-R1 topped the free charts in the US App Store. Nvidia’s market value evaporated by approximately $593 billion, marking one of the largest single-day market value losses in US history.
At that moment, DeepSeek appeared as a bullet shot from Hangzhou towards Silicon Valley. It proved something that made many uncomfortable: cutting-edge AI does not necessarily require astronomical computing power and capital. At least at that time, a Chinese team used extreme engineering optimization, MoE, reinforcement learning, and open-source strategies to puncture the narrative that “the more expensive the computing power, the stronger the model” that Silicon Valley had built over the past two years.
However, 484 days later, the story became convoluted.
The team that had burst onto the scene with a low-cost myth began discussing financing. The lab that had rejected VCs, avoided going public, and relied on funding from Huanfang Quantitative was now surrounded by Tencent and Alibaba at the negotiating table. The model company that had earned global developer respect through open-source found its models being integrated into products, entering commercial systems, while it still needed to find a price anchor for employee options.
Even more convoluted was that the low-cost myth itself came with a price tag. The $5.57 million figure was real, but it did not represent DeepSeek’s entire bill. SemiAnalysis later estimated that DeepSeek’s total hardware expenditure exceeded $1.3 billion, with a GPU cluster of about 50,000 units, including H800, H100, and H20 mixed resources.
In other words, the $5.57 million was more like a pretty receipt stating how much this training cost, without mentioning how much had been burned beforehand to make this training happen.
Thus, the truly noteworthy aspect of DeepSeek over these 484 days is not the grand narrative of “China’s AI rise”; that would be too simplistic.
The 484 days do not tell the story of DeepSeek’s growth from small to large, but rather resemble a journey of a technological idealist who must learn to navigate the gravity of the real world and conquer it.
People: The Departed and Their Direction
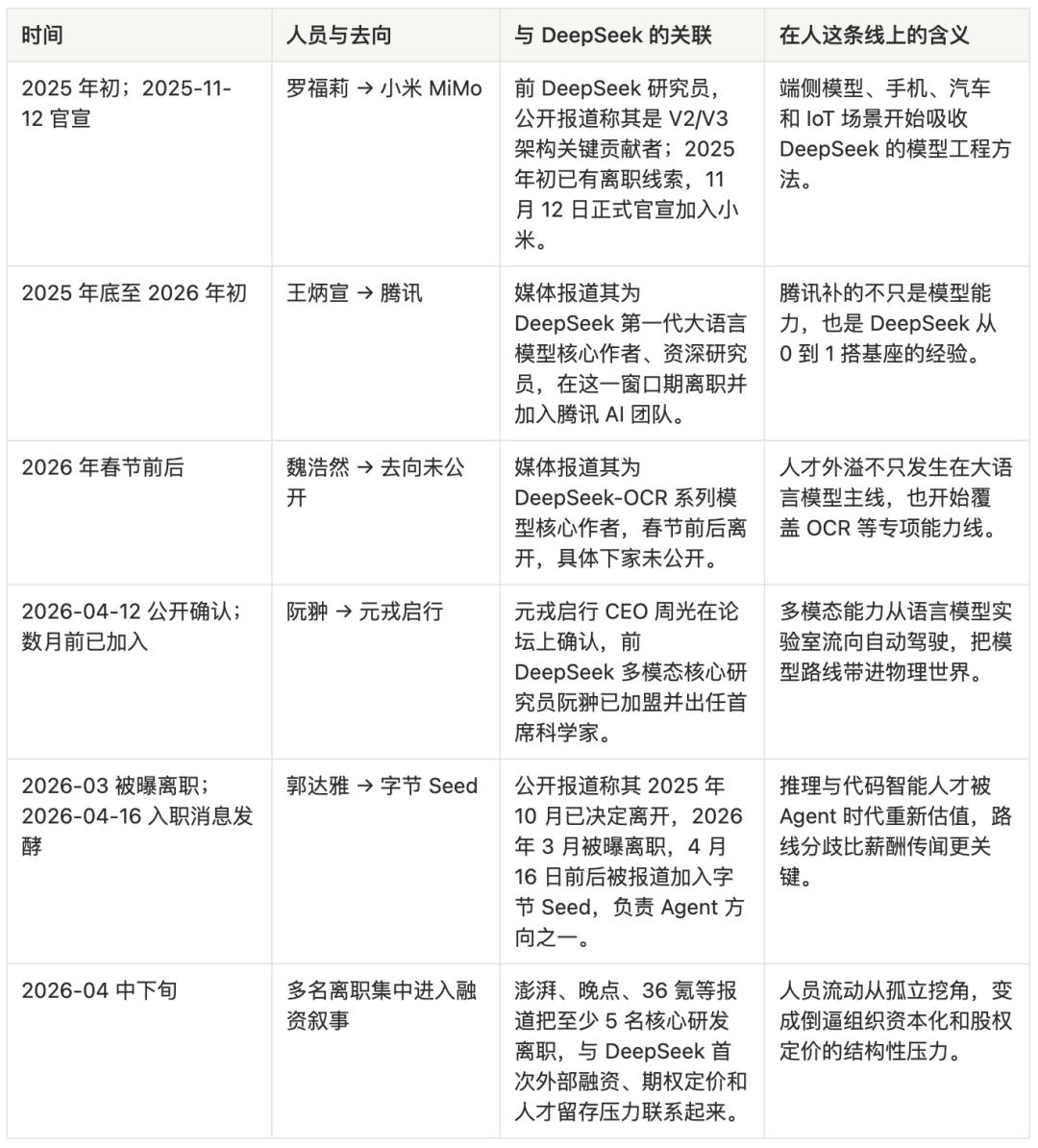
On April 16, 2026, the news broke that Guo Dayan had joined ByteDance’s Seed team.
If DeepSeek-R1 is seen as the product that truly broke through globally for DeepSeek, then Guo Dayan cannot be treated as just an ordinary departing employee. Public reports referred to him as a significant contributor to R1’s inference capabilities, particularly related to the GRPO reinforcement learning method. ByteDance’s direction for him was also subtle: Agent. The rumors of a “hundred million annual salary” were later refuted by Douyin’s vice president Li Liang, but the gossip had already served its purpose. It provided the public with a direct view: DeepSeek’s talent was beginning to be priced.
Before this, DeepSeek’s image resembled that of a hidden sect in a martial arts novel. Huanfang Quantitative was providing funding from behind, Liang Wenfeng had sufficient resources, and researchers focused on model development without urgency for products or commercialization. While other startups were busy raising funds, making lists, developing applications, and building ecosystems, it remained a silent computing power monk, meditating, pushing formulas, and training models.
However, the AI industry does not respect monks for long, especially when they possess genuine knowledge. From late 2025 to early 2026, multiple core members of DeepSeek were reported to have left: Luo Fuli went to Xiaomi MiMo, Wang Bingxuan went to Tencent, Ruan Chong went to Yuanrong Qixing, Wei Haoran’s whereabouts are unknown, and Guo Dayan went to ByteDance Seed. These departures collectively form a map of the next battlefield in China’s AI: Luo Fuli corresponds to the endpoint and Xiaomi’s “phone + car + IoT” closed loop; Ruan Chong corresponds to multi-modal perception in autonomous driving; Guo Dayan corresponds to Agent; Wang Bingxuan corresponds to Tencent’s anxiety about rebuilding its AI foundation.
Money, of course, is important. Large companies can offer higher cash salaries, clearer option buybacks, and more mature promotion systems.
ByteDance’s first repurchase price for Doubao stock increased by 30.8% compared to the grant price, which feels more like a paycheck to a researcher than the promise of “we will change the world in the future.” DeepSeek’s problem here becomes specific: it can attract talent with technological idealism, but it struggles to pay the opportunity costs of that talent in the long term, especially as peers’ wealth stories begin to materialize. Companies like Zhipu, MiniMax, and Yuezhianmian are being revalued by the capital market. The financing numbers for OpenAI and Anthropic hang in the news headlines like astronomical phenomena. A post-95 researcher sees friends receiving cashable options while their own DeepSeek options lack a public market price, creating a psychological gap that cannot be erased by “purely doing research.”
More critically, those leaving are not just being lured away by money; they are also taking their directions with them.
DeepSeek’s strongest aspects lie in its base models, inference models, and its ability to minimize training and inference costs. Its organizational culture naturally leans towards one goal: making the model itself stronger, cheaper, and more open-source. This is undoubtedly cool. However, after 2025, the industry’s excitement began to shift. People were no longer satisfied with “the model can answer questions”; they wanted models that could write code, call tools, execute tasks across applications, remember context, and form closed loops in products. Agent transitioned from an overhyped term to an entry point for the next generation of product structures.
At this point, DeepSeek’s advantages became a constraint. A researcher wanting to study Agents would face a more foundational organization within DeepSeek, while at ByteDance, they would engage with a real user base of 157 million monthly active users. A multi-modal researcher wanting to enable models to understand the physical world might find more allure in an autonomous driving company than in continuing to scale up language models. An endpoint model researcher aiming to embed inference capabilities in mobile devices, vehicle systems, and home appliances would find Xiaomi more like a laboratory than DeepSeek. This is not about betrayal; it’s a natural divergence following a fork in the technological route.
Bell Labs serves as a similar reference. It nurtured transistors, information theory, Unix, and the C language, while also spilling over generations of talent. Those who left Bell Labs did not destroy it; rather, they spread its methodologies throughout the American tech industry. DeepSeek’s talent outflow may be doing the same. The difference is that Bell Labs had AT&T’s monopoly profits behind it, while DeepSeek is backed by Huanfang Quantitative. No matter how strong Huanfang is, it is not a public finance entity that can endlessly fund the Chinese AI industry.
Liang Wenfeng faces a very real problem: if DeepSeek truly wants to retain talent, it must assign a price to its equity; if DeepSeek’s equity is to have a price, it must enter the capital market’s language system; if it enters the capital market’s language system, it must accept the capital market’s inquiries: how do you make money? How do you grow? How do you prevent others from profiting from your open-source models?
This is why DeepSeek’s financing pressure is not merely about “lacking money”; it resembles an identity transformation. It needs to shift from a research organization that “does not need to explain itself to anyone” to one that must explain itself to employees, shareholders, cloud vendors, chip manufacturers, developers, and regulators as a foundational infrastructure company.
This step is not romantic. However, it may determine DeepSeek’s fate more than the viral success of R1.
Finance: The Myth of $5.57 Million Must Be Settled
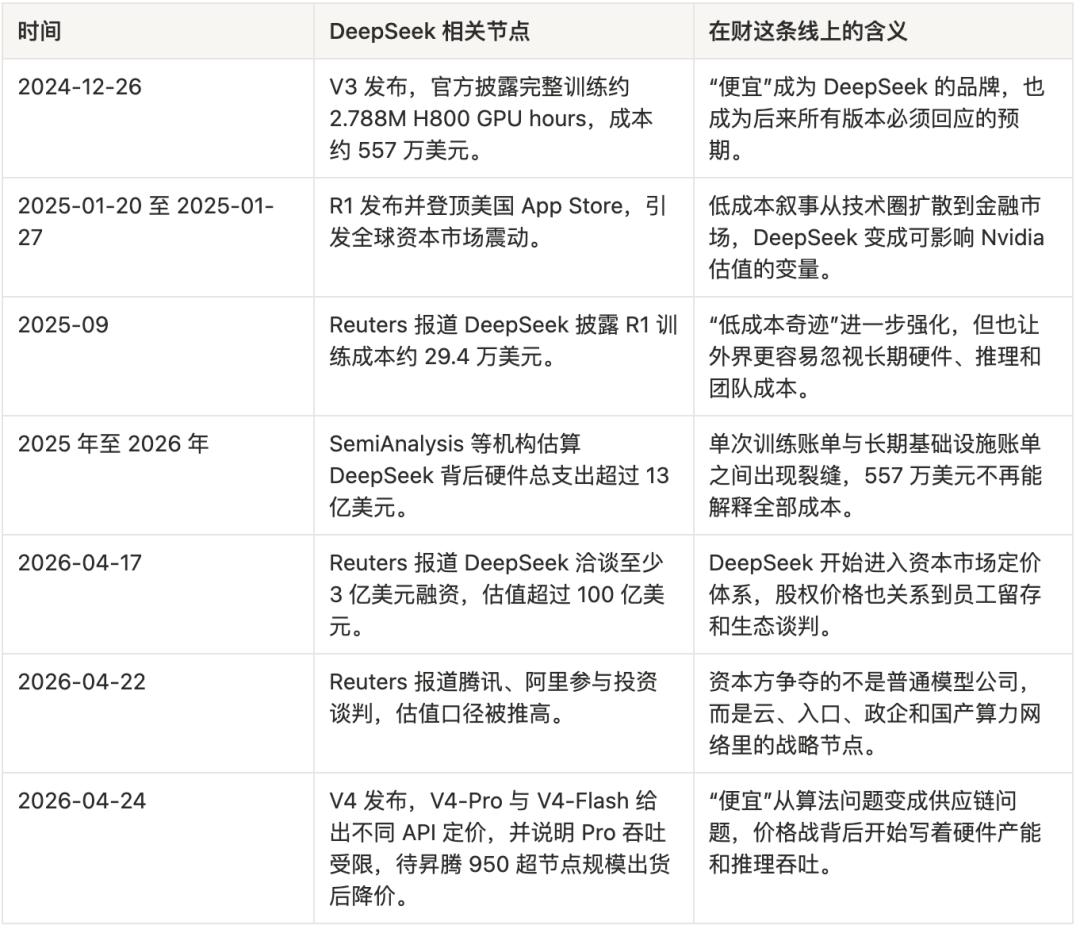
DeepSeek’s most dangerous achievement is that it has turned “cheap” into its brand.
This has been validated countless times in Chinese manufacturing: while China’s manufacturing industry contributes to making expensive goods affordable for ordinary people, the inverse is also true—price and profit can constrain the pace of industrial upgrades.
This phenomenon is fully replayed in DeepSeek.
In recent years, the capital expenditures of OpenAI, Anthropic, Google, and Meta have left many in shock. Hundreds of billions in capital expenditures, valuations in the trillions, and data centers with hundreds of thousands of GPUs all culminate in one statement: intelligence is expensive.
Until December 26, 2024, when DeepSeek-V3 was released, this statement suddenly became unstable.
$5.57 million.
This figure is too suitable for dissemination. It is short, sharp, and impactful, like handing Silicon Valley a sarcastic poster: while you burn hundreds of billions, we create a capable model with just a fraction of that. R1 further exaggerated this narrative. In September 2025, Reuters reported that DeepSeek disclosed in a Nature paper that R1’s training cost was only about $294,000. Thus, DeepSeek was placed into a neat narrative box: a low-cost miracle.
The problem is that the low-cost miracle can constrain itself.
The first layer of constraint comes from public expectations. When you make the world tremble with $5.57 million, the next time you release a model, people will not only ask if it is strong but also if it is cheap enough. If V4 shows significant capability improvement but skyrockets in cost, DeepSeek’s story will crack. Conversely, if V4 is not impressive enough to maintain the low-cost narrative, it will fail to meet the expectations of the capital market and industrial ecosystem. This is akin to a chef who prepares a Michelin-quality meal for $10. The first meal is a miracle. Starting from the second meal, all guests will ask: can you continue to do it for $10? If it rises to $100, they will say you have changed; if you still charge $10, you will go bankrupt.
The second layer of constraint comes from actual costs. The $5.57 million corresponds to GPU hours within a single training process, excluding earlier architectural explorations, failed experiments, data construction, engineering teams, hardware reserves, inference services, and the costs of scaling up after user surges. SemiAnalysis estimated that DeepSeek’s total hardware expenditure exceeds $1.3 billion, which is a figure closer to the material foundation required for a cutting-edge model company to exist long-term.
Huanfang Quantitative can provide funding for DeepSeek. In 2025, Huanfang Quantitative’s average return rate was reported by several media outlets to be around 56.55%, with annual revenue estimated at nearly 4.9 billion RMB, and Liang Wenfeng’s shareholding ratio was sufficiently high. For an ordinary AI lab, this is already a dream investor.
However, after V4, DeepSeek’s cost structure changed. Trillion parameters, million-token context, Agent capabilities, domestic chip adaptation, global open-source developer ecosystem, and stable APIs for enterprises will not only appear in training bills. They will become inference costs, engineering costs, customer support costs, compliance costs, channel costs, and talent costs. Training a model once is like going to war; long-term service to an ecosystem is like garrisoning troops. Garrisoning is more expensive than fighting because it incurs daily costs.
This is also why DeepSeek’s financing suddenly became reasonable in April 2026. Reuters first reported The Information’s news, stating that DeepSeek was negotiating at least $300 million in financing, with a valuation exceeding $10 billion. Days later, news emerged that Tencent and Alibaba were participating in negotiations, pushing the valuation figure above $20 billion, with Tencent reportedly proposing to acquire up to 20% of the shares but was refused. Chinese venture capital circles provided even more stimulating versions: a pre-investment valuation of 300 billion RMB, a planned capital increase of 50 billion RMB, with external funding of 30 billion and internal funding of 20 billion, with a minimum investment of 5 billion.
These figures may not all receive official confirmation, but they collectively point to one thing: DeepSeek is no longer just a star company pursued by capital; it is becoming a strategic node that giants must compete for. For Alibaba, DeepSeek can enhance the narrative of cloud and AI infrastructure. For Tencent, DeepSeek can fill the awkwardness of mixed elements in the C-end mindset. For both companies, DeepSeek is a rare entity: it was not incubated by a large company but has already gained global developer reputation; it has not fully commercialized but possesses a foundational infrastructure position; it offers open models while making all users prove its irreplaceability.
This is also why the 5 billion minimum investment threshold is so interesting. If this threshold is true, it filters out not those with less money but those who only want financial investments.
DeepSeek seeks resource-based shareholders: cloud computing power, government and enterprise clients, compliance endorsements, chip supply chains, and model distribution channels. Money is just the easiest quantifiable part of this. This is somewhat similar to SpaceX’s transformation. Early on, SpaceX needed to prove that rockets could fly cheaper. After successful technical validation, it required NASA contracts, commercial launch orders, Starlink cash flow, and national security orders even more. Cheapness is not the end; it is merely the first step to open the gap in the old order.
DeepSeek is also in a similar position. The $5.57 million training cost is not the answer to its future business model; it is merely the bullet. The bullet pierced Silicon Valley’s computing power myth and also penetrated DeepSeek’s protective shell. The bullet proved that cutting-edge AI can be cheap, but it did not prove that a cutting-edge AI company can survive cheaply forever.
The Business: Open-Source Models as Others’ Weapons
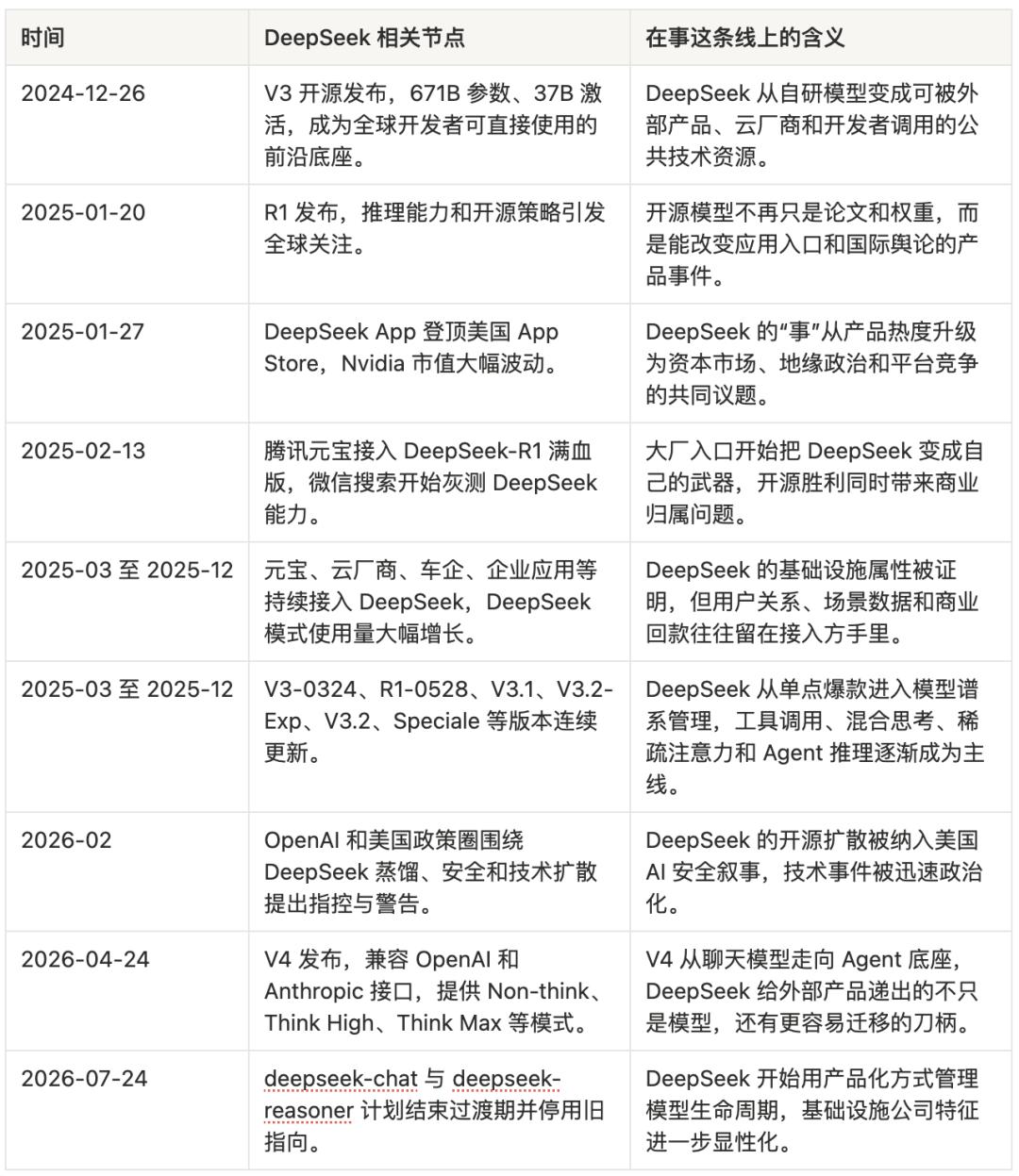
In January 2025, DeepSeek’s story first became a global public event.
After R1’s release, the DeepSeek App surged to the top of the US App Store’s free charts. TechCrunch wrote directly: DeepSeek replaced ChatGPT as the top app in the App Store. Reuters recorded another figure in financial history: Nvidia’s market value evaporated by approximately $593 billion. This moment had a strange comedic aspect. A Chinese open-source model made American retail investors begin to question Nvidia’s valuation, forced Silicon Valley to reinterpret its capital expenditures, prompted OpenAI and Microsoft to investigate “distillation” issues, and placed a Hangzhou team into the narrative of technological security in the US. Before DeepSeek could commercialize, it was geopoliticized.
However, a more interesting event occurred in China. On February 13, 2025, Tencent Yuanbao integrated the full version of DeepSeek-R1. This marked Tencent’s first deployment of a third-party open-source model in its own AI assistant. Users could switch between Yuanbao and DeepSeek, and WeChat search began to test integration with DeepSeek.
Before this, Tencent’s AI situation was somewhat awkward. It had Yuanbao, computing power, WeChat, a content ecosystem, cloud resources, and organizational assets. However, in users’ minds, the domestic AI product heat was more occupied by Doubao, Kimi, Tongyi, and DeepSeek. Tencent’s strongest asset was its entry point, but it lacked an AI symbol that could excite users. DeepSeek was precisely that symbol.
After Yuanbao integrated R1, downloads surged, exceeding the DeepSeek App itself by early March. User enthusiasm during the WeChat search test with DeepSeek was described by the media as “far exceeding expectations.” By the end of 2025, the daily usage of Yuanbao’s DeepSeek mode reportedly reached an annual peak, increasing over 100 times since the beginning of the year.
This was not DeepSeek being saved by Tencent; it was Tencent saving its own AI product line using DeepSeek.
Yet, DeepSeek did not walk away empty-handed. It gained something more subtle: a proof of factual standards. When China’s largest social entry point chooses to deploy your model in its product, when users complete searches and Q&A through your model in the WeChat ecosystem, and when other large companies, car manufacturers, telecom operators, and cloud vendors rush to integrate, you are no longer just a strong open-source model on GitHub. You become part of the public infrastructure.
The problem lies here. Public infrastructure sounds advanced, but it can be commercially uncomfortable. The sharpest aspect of an open-source model is that it allows everyone to use you. The most brutal aspect of an open-source model is that it allows everyone to use you.
Tencent can integrate DeepSeek into Yuanbao. Alibaba can embed DeepSeek into its cloud services. Startups can use DeepSeek as a code assistant. Government and enterprise clients can privatize deployment via cloud vendors. Developers can locally distill, fine-tune, and quantify. Each instance of use expands DeepSeek’s influence.
However, each instance of use may also bypass DeepSeek’s revenue stream. This is the moment when the costs and benefits of open-source are simultaneously realized. The more DeepSeek’s model resembles water and electricity, the more awkward its commercial identity becomes. Water and electricity are vital, but companies that sell water and electricity are typically not the most attractive companies. The real money is often made by those who connect water and electricity to cities, factories, commercial real estate, and residential billing systems. In AI, these people are called cloud vendors, entry platforms, Agent products, enterprise software, and vertical applications.
After the release of V4, this logic of “others taking it to make weapons” became clearer. V4-Pro and V4-Flash simultaneously provide compatibility with OpenAI ChatCompletions and Anthropic interfaces; the new model names are deepseek-v4-pro and deepseek-v4-flash; the old deepseek-chat and deepseek-reasoner will be discontinued after a three-month transition period. This is not a model solely for its own app but one prepared for migration, replacement, and embedding from the interface level. Developers can redirect applications originally connected to OpenAI or Anthropic to DeepSeek, cloud vendors can package it as an API, and Agent products can automatically switch complex tasks to Think Max.
In other words, while DeepSeek hands others knives, it also sharpens the handles.
The technical route is also converging in this direction. V3-0324 enhances reasoning, front-end code, and tool invocation; R1-0528 reduces hallucinations and improves JSON and function calling; V3.1 introduces a Think / Non-Think hybrid mode, strengthening Agent capabilities and supporting Anthropic API formats; V3.2-Exp introduces Sparse Attention, significantly reducing costs; V3.2 and Speciale further target Agent reasoning scenarios.
By the time of V4, three levels of thinking intensity are directly productized: Non-think corresponds to everyday quick responses, Think High corresponds to complex planning, and Think Max corresponds to high-intensity reasoning and Agent tasks. DeepSeek even retains complete reasoning content in tool invocation scenarios, including multi-turn reasoning history across user message boundaries. This design is not prepared for a “chatbot” but for real workflows like long-term tasks, code engineering, document generation, and search planning.
The evaluations of V4 are also very indicative. It does not only tell stories through traditional rankings like MMLU but also showcases Agentic Coding, Terminal Bench, SWE Verified, MCPAtlas, white-collar tasks, and Chinese professional writing.
According to technical breakdown materials, V4-Pro-Max scored 67.9 on Terminal Bench 2.0, 80.6 on SWE Verified, and 76.2 on SWE Multilingual, overall placing it in the same tier as Opus-4.6-Max and K2.6-Thinking; in real R&D tasks among over 50 internal engineers, V4-Pro-Max’s pass rate was 67%, close to Opus 4.5’s 70% and higher than Sonnet 4.5’s 47%.
The significance of these numbers lies not in “winning scores” but in answering a more industrial question: can the new model integrate into the daily production of engineering teams?
This also explains DeepSeek’s dilemma. It certainly knows that pure model capabilities will be used by others to create products, which will accumulate users, data, workflows, and distribution advantages. If a model company only remains in the position of an arms dealer, it will be pressured on price by all those buying arms.
However, DeepSeek’s uniqueness lies in its inability to easily transform into an ordinary application company. If it engages in C-end products, it must compete with Doubao, Kimi, Yuanbao, and Tongyi for entry points; if it develops code products, it must compete with Cursor, Claude Code, Codex, and various domestic IDE plugins for workflows; if it ventures into enterprise software, it must begin facing sales, delivery, customization, and payment issues in the mud. An organization skilled at optimizing models to the extreme may not excel at rolling in the mud.
Thus, DeepSeek’s “business” line has become a chain reaction: R1’s viral success triggered global stock market tremors; global tremors prompted a backlash from US IP and security narratives; domestic integration spurred large companies to collectively adopt DeepSeek; large companies’ integration validated DeepSeek’s infrastructure value; infrastructure value, in turn, compelled it to address commercialization issues.
OpenAI warned the US Congress that DeepSeek was gaining capabilities through distillation, and the White House accused China of “industrial-scale AI technology theft”—these are certainly part of the geopolitical narrative. However, if viewed solely from this dimension, one might miss the more specific industrial issues. DeepSeek has shown everyone for the first time that open-source models can rapidly change product landscapes globally, while also demonstrating that the victory of open-source models may not automatically belong to open-source model companies.
This situation is somewhat akin to Android. Android provided global smartphone manufacturers with an operating system to counter the iPhone, completely rewriting the entry landscape of the mobile internet. However, the long-term beneficiaries were not every Android smartphone manufacturer but Google, which controlled the app store, advertising system, account system, and cloud services.
DeepSeek is standing in a similar position. It provides a foundational layer. However, the cities above that foundational layer are being rapidly constructed by others.
The Material: From H800 to Ascend, A Chip Replacement Surgery
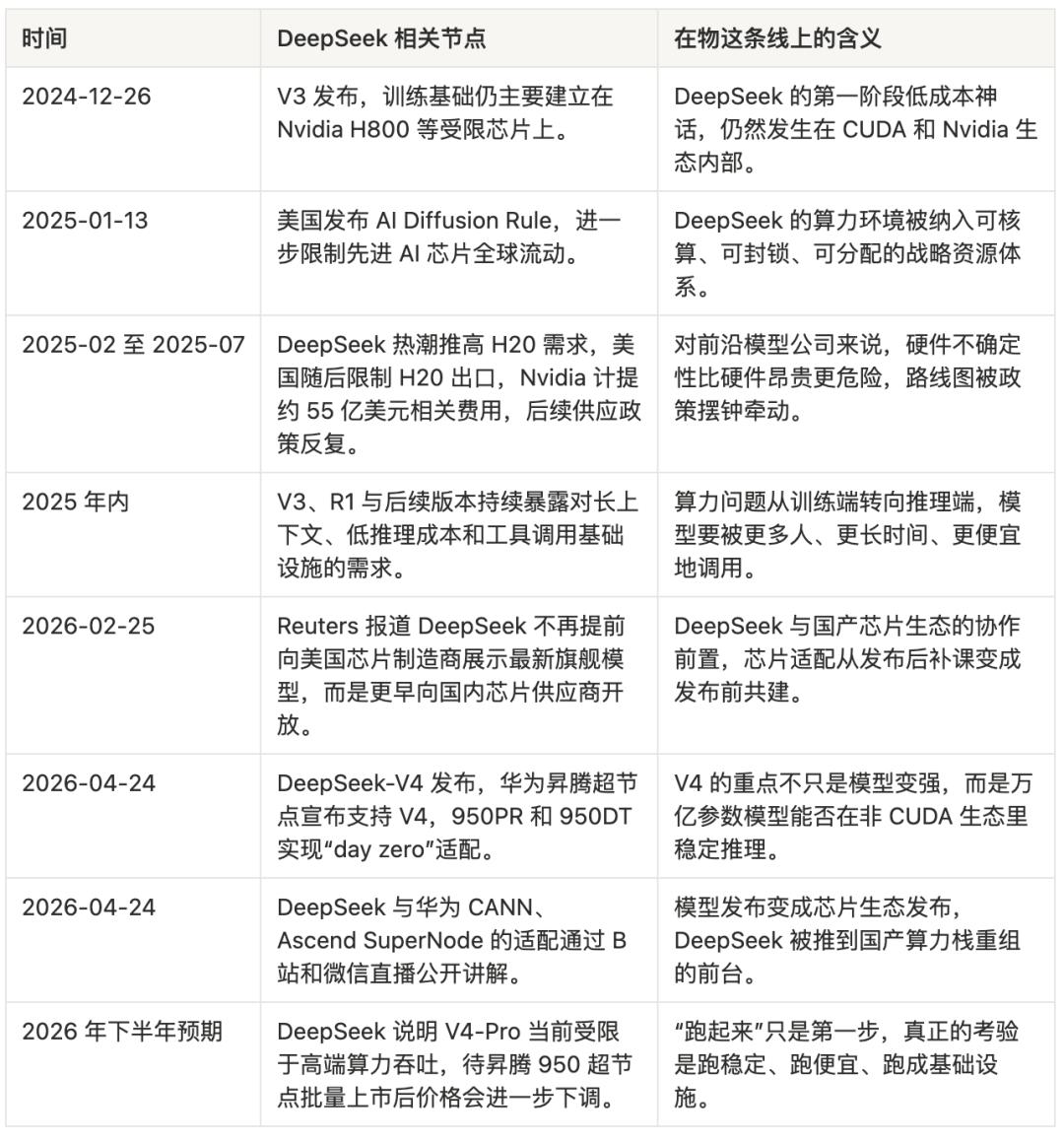
The most important parameter of DeepSeek-V4 may not be 1.6 trillion. It is Ascend.
This does not imply that model capability is unimportant. V4-Pro adopts a total of 1.6 trillion parameters and 49 billion active parameters in its MoE architecture, while V4-Flash features 284 billion total parameters and 13 billion active parameters. Both support a million-token context, and the model card indicates the use of CSA + HCA mixed attention mechanisms. V4’s technical report also includes mHC manifold constraint superconnection, DSA sparse attention, Muon optimizer, FP4 quantization-aware training, On-Disk KV Cache, deterministic kernel library, and DSec sandbox infrastructure.
When these terms are piled together, they can easily devolve into technical self-indulgence. However, in the industrial context of April 2026, they all serve a harder fact: V4 needs to run, stabilize, and run cheaply on domestic computing power.
DeepSeek-V3’s material foundation still relied on Nvidia H800. Under restricted chip conditions, it maximized efficiency through MoE, MLA, FP8, and extensive bottom-level optimizations. Developers discovered traces of PTX low-level optimization in V3’s code, indicating that DeepSeek had long been bypassing the comfort zone of high-level frameworks to directly engage with GPU execution layers. PTX is the low-level intermediate representation for Nvidia GPUs. A team willing to engage at this level signifies that it is not merely a model team adjusting framework parameters but an engineering team capable of performing surgical operations on computing power infrastructure.
This capability became crucial for V4. The US chip blockade has evolved from “not providing the strongest chips” to “giving you a total bill.”
On January 13, 2025, the Biden administration released the AI Diffusion Rule, placing global AI chip flows under tiered control. Reuters reported that this set of rules aimed to restrict the diffusion of advanced AI chips globally, with China placed in a strictly limited position. Subsequent discussions regarding limitations on TPP total processing performance essentially turned computing power into a strategic resource that can be accounted for, blocked, and allocated. This logic is very American. It does not necessarily aim to completely prevent your development; it merely seeks to ensure you lag a generation.
The tug-of-war over H20 is a small window. In February 2025, Chinese companies increased H20 orders due to the DeepSeek frenzy. In April, the US restricted H20 exports, and Nvidia recorded approximately $5.5 billion in related expenses. By May, Nvidia prepared a downgraded version. In July, Jensen Huang stated that supply would be restored.
By April 2026, the US Secretary of Commerce confirmed that H200 had not yet been sold to China. This is not about stabilizing supply chains; it binds a company’s training plans to Washington’s policy pendulum. For a cutting-edge model company, this uncertainty is more dangerous than high costs. High costs can be financed, but uncertainty can destroy a roadmap.
Thus, DeepSeek’s shift to Huawei Ascend is not merely a patriotic narrative or emotional value from the launch event. It is a rational choice for a model company facing supply chain risks.
In February 2026, Reuters reported that DeepSeek no longer followed industry norms by previewing its flagship models to American chip manufacturers but instead opened up to domestic chip suppliers earlier. In April, Reuters reported that DeepSeek-V4 would run on Huawei chips and that it was rewriting and testing the underlying code with domestic chip manufacturers. On the same day of V4’s release, news emerged that Huawei’s Ascend supernodes would fully support DeepSeek-V4.
SCMP described this “premiere adaptation” directly: Huawei stated that the Ascend 950PR and 950DT achieved “day zero” adaptation for DeepSeek-V4; during live streams on Bilibili and WeChat, Huawei engineers explained the adaptation process between CANN and DeepSeek V4, claiming that the entire Ascend SuperNode product line had been “fully adapted” to V4’s model inference. This statement requires careful examination.
“Day zero” sounds like marketing, but for a trillion-parameter model, it means that the hardware ecosystem can catch up with the model’s release on the same day; “fully adapted” does not equate to perfect performance, but it at least signifies that the software stack, inference framework, and underlying operators have established the first layer of production pathways. More interestingly, DeepSeek itself acknowledged that before the large-scale shipment of the Ascend 950PR supernode in the second half of the year, V4-Pro would face throughput issues, and prices would significantly decrease after the hardware was released in bulk. This is not a victory declaration but resembles a construction timeline: the direction is correct, the road is still expanding, but for now, traffic must be limited.
Transitioning from CUDA to CANN is not simply about copying model files. It requires operator rewriting, compiler adaptation, inference framework optimization, communication interconnection scheduling, memory management, and verification of long-context performance. Especially for a trillion-parameter model like V4, any inefficiency in any link can turn “domestic adaptation” into a PPT adaptation. A technical analysis reprinted by TMT suggests that V4’s repeated delays are related to the deep adaptation between the inference end and Ascend chips; the real challenge lies not in whether it can run, but in whether it can run stably, efficiently, and at scale.
This is why Jensen Huang stated that DeepSeek running on Huawei chips is a “horrible outcome” for the US. TNW’s interpretation of this statement is more straightforward: DeepSeek spent months rewriting core code to adapt to Huawei’s CANN framework, moving away from the CUDA ecosystem that took twenty years to build. The dominance of CUDA itself is a second layer of control that the US holds beyond chips.
Nvidia’s true fear is not that Chinese companies can create a strong model. A strong model can be explained as accidental, distilled, subsidized, or unsustainable. What it fears is a strong model running stably in a non-CUDA ecosystem. Because CUDA’s moat is not just chip performance; it encompasses developer habits, toolchains, ecosystems, debugging experiences, operator libraries, training frameworks, and talent markets. As long as Chinese model companies continue to optimize around CUDA, US chip controls will have leverage.
The technical details of V4 also explain why this chip replacement surgery is challenging. The primary cost of a million-token context is not whether the model is intelligent but how much historical information must be processed during each inference. Traditional attention mechanisms can turn KV cache and FLOPs into disaster zones in long contexts. DeepSeek-V4 compresses at the token dimension and adds DSA sparse attention. Technical breakdown materials indicate that under 1M context, V4-Pro’s single-token inference FLOPs are only 27% of V3.2’s, and KV cache is only 10% of V3.2’s; V4-Flash is even more extreme, with single-token FLOPs only 10% of V3.2’s and KV cache only 7%. This is the true significance of V4’s binding to Ascend: without a structural reduction in long-context inference costs, even if domestic computing power can run, it will be challenging to run it cheaply.
Previously, I wrote an analysis on Foxconn’s transformation, noting that the judgment of transformation is never about what you “assemble” but about what you control in the value chain.
Foxconn’s shift from iPhones to AI servers changed the assembly objects but not the profit position. In contrast, DeepSeek and Ascend’s story is about attempting to change its position within the underlying ecosystem. As long as the model team continues to think in CUDA’s language, domestic chips can easily become “rebranded OEMs”; only when the model architecture, inference framework, operator libraries, and communication scheduling are all rewritten around local hardware characteristics can it potentially evolve from “replaceable hardware” to “self-evolving systems.”
This is also the most awkward aspect of blockade policies. In the short term, they can indeed create pain. They can increase costs, slow adaptation, disrupt supply chains, and force companies to take difficult paths. However, if the blockaded side possesses a sufficiently large market, enough engineers, strong demand, and clear alternative goals, the blockade can become an industrial mobilization. The significance of DeepSeek-V4 lies here.
It is not the endpoint of the domestic computing power ecosystem; it is the first time the scalpel has cut to the bone.
Conclusion: After Cheapness
The past 484 days of DeepSeek can easily be misread as a victory story.
A Chinese team created a strong model at a low cost, shattered Nvidia, shook Silicon Valley, pressured the US, boosted domestic chips, and ultimately led Tencent and Alibaba to line up with money. Writing this version would be satisfying for readers and easy to title. However, this version is too light. The truly interesting aspect is that each of DeepSeek’s victories carries a counteraction.
The low-cost victory of V3 necessitates continued proof that cheapness can be sustained; the global viral success of R1 imposes responsibilities far beyond laboratory scale in terms of users, public opinion, and geopolitical pressure; the victory of open-source allows Tencent, Alibaba, car manufacturers, and cloud vendors to turn it into their weapons; the victory of talent results in researchers trained by it being precisely priced by the entire industry; the victory of domestic adaptation transforms it from a model company into a wedge for restructuring the chip ecosystem; the victory of financing finally brings Liang Wenfeng to the table he initially deliberately avoided.
This is not the failure of idealism. On the contrary, only if the first 484 days were sufficiently idealistic could DeepSeek have negotiating chips on the 485th day.
If it had initially followed the typical AI startup route—financing, product development, commercialization, and chasing trends—it would likely have become just another company at the crowded table of Chinese large models: doing a bit of modeling, a bit of application, discussing a bit of ecosystem, testing a bit of commercialization, touching on everything but excelling at nothing.
What Liang Wenfeng truly won is the ability to push the technological boundary far enough before returning to negotiate terms with reality. However, reality will not become gentle simply because you have won once. The $5.57 million is a bullet. It pierced Silicon Valley’s moat and also penetrated DeepSeek’s protective shell. The bullet proved that cutting-edge AI can be cheap, but it did not prove that a cutting-edge AI company can live cheaply forever.
After 484 days, DeepSeek is no longer just a “low-cost miracle.” It is an open-source foundation used by global developers, a capital target fiercely contested by Tencent and Alibaba, a geopolitical symbol under scrutiny by the US Congress and the White House, and a trillion-parameter model undergoing a chip replacement surgery on domestic chips. Its situation has thus become more like a compressed sample of China’s AI: idealism needs money, open-source requires a moat, localization demands engineering accountability, and low-cost must continue to be low.
Liang Wenfeng once said that DeepSeek is not aimed at short-term profitability but at pushing the boundaries of technology. After 484 days, the technological boundaries have indeed been pushed forward.
Yet what drives it forward now is no longer just technology.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.